Synchronizing on Strings and String interning
I’ve recently had to solve a problem of synchronizing a piece of code on some String objects in Java. Here’s a short description: “In a network management system, you need to handle different events produced for different IPs. Code must support multithreading, but if more events are generated at the same time for the same IP, you must handle those events in original order, one at a time. IPs are stored as String objects”.
Now, let’s say the method signature is public void process(String ip, Event event). It’s obvious that you shouldn’t make the entire method synchronized because it won’t be multithreaded anymore. The first thing that might come to your mind can be to add a block like synchronized(ip) { … process event … } . Please note that String objects are immutable and, for the same IP value (eg. “11.111.11.1”), you might have two different String objects. So, synchronizing on ip directly would not be a good idea.
What you might not know is that Java supports String interning : “a method of storing only one copy of each distinct string value, which must be immutable. Interning strings makes some string processing tasks more time- or space-efficient at the cost of requiring more time when the string is created or interned. The distinct values are stored in a string intern pool.” The corresponding method in Java is String.intern() which checks if the string pool contains a value equal to the String object for which the method is called as determined by the String.equals(Object) method. If String object is found, the method returns the reference to the object from the pool. If string not found, then it’s first added to the pool and a reference is returned.
Java automatically interns String literals. This means that in many cases, the == operator appears to work for Strings in the same way that it does for ints or other primitive values, but it is strongly recommended to use String.equals(Object) method (which by the way is first checking if object references are the same). The intern() method is to be used on Strings constructed with new String(). Here are some examples of String interning:
String s1 = "test";
String s2 = "test";
String s3 = "test".intern();
String s4 = new String("test");
String s5 = new String("test").intern();
String result = "Testing String interning: \n";
result += (s1 == s1) ? "s1 and s2 are identical \n" : ""; // true
result += (s1 == s3) ? "s1 and s3 are identical \n" : ""; // true
result += (s1 == s4) ? "s1 and s4 are identical \n" : ""; // false
result += (s1 == s5) ? "s1 and s5 are identical \n" : ""; // true
There are some disadvantages of interning strings:
- you must ensure that intern() method is called for all the strings (except string literals or constants) that you’re going to compare. Someone using your code might forget to intern strings and confusingly results might be returned.
- intern() calls are quite expensive because it has to manage the pool of strings
So, please make sure you know what you are doing before starting using interning.
Going back to our problem, String interning can help us synchronizing on IPs. Here’s how our method should look like:
public void process(String ip, Event event) {
// ...
synchronized(ip.intern()) {
// process event
}
// ...
}
You might think everything is fine with this piece of code, but, by interning a String, it turns into a global object and if you’re synchronizing on the same interned string in different parts of your application, you can end up with deadlocks. There’s a small probability for this to happen, but you must take it into account that anybody can add a piece of code like that outside your module and you won’t even notice it.

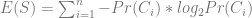
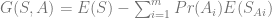



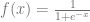
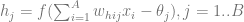
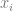 are the network inputs,
are the network inputs,  are the weights,
are the weights, 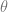 is the activation function threshold,
is the activation function threshold,  the inputs number and
the inputs number and 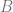 the hidden neurons number.The output layer results are calculated using this formula:
the hidden neurons number.The output layer results are calculated using this formula: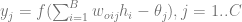
 was calculated before and
was calculated before and  is the output layer’s neurons number.
is the output layer’s neurons number.

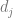 is the network expected output.The weights for the next step are adjusted as follow:
is the network expected output.The weights for the next step are adjusted as follow: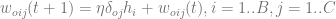

 is the learning rate.
is the learning rate.










